AWS is Down - Here's How To Bulletproof Your Company For Web Outage In Three Steps


According to the AWS status page, there's been an increased rate of errors reported on Tuesday morning.
A stable infrastructure is critical to a stable business. Due to frequent changes, security and stability are key elements that allow you to focus on business. Here's how to bulletproof your business in three steps in case it happens again.
1. Implement an HA (High Availability) infrastructure across multiple regions
A high availability cluster architecture consists of four key components:
1. Load balancing
A highly available system must have a carefully designed, pre-engineered mechanism for load balancing to distribute client requests between cluster nodes. The load balancing mechanism must specify the exact failover process in case of a node failure.
2. Data scalability
A highly available system must take into account the scalability of databases or disk storage units. The two popular options for data scalability are using a centralized database and making it highly available with replication or partitioning; or ensuring that individual application instances can maintain their own data storage.
3. Geographical diversity
In today’s IT environment – especially with cloud technology being so available – it is essential to distribute highly available clusters across geographical locations. This ensures the service or application is resilient to a disaster affecting one physical location, because it can failover to a node in another physical location.
4. Backup and recovery
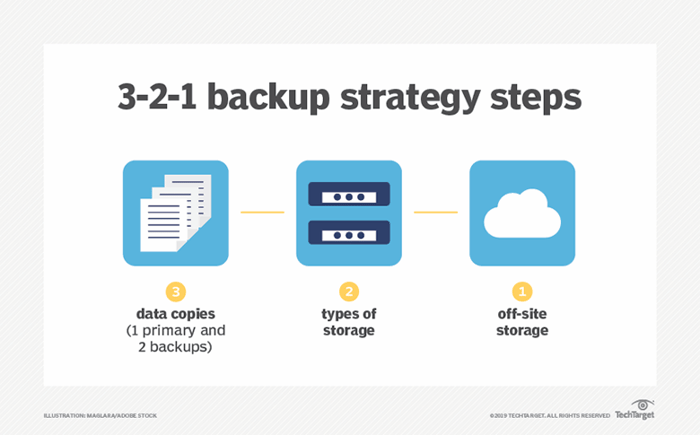
Highly available architectures are still subject to errors that can bring down the entire service. If and when this happens, the system must have a backup and recovery strategy so that the entire system can be restored within a predefined recovery time objective (RTO). A standard rule for backups known as “3-2-1” states that you should keep three copies of the data, on two media types, in one geographical location. Using Cloud we can add additional geographical locations, so the model could be changed to 3-2-x - where the x is the number of geolocation of backup.
2. Perform regular tests of infrastructure resistance to potential outages and attacks
Each company’s infrastructure changes regularly. It does not only mean launching new servers but also gaining new users, establishing new connections and implementing new authentication methods – each new component increases the attack surface and increases the number of potential attacks such as DDoS, code injections and other attacks that exploit infrastructure vulnerabilities.
Infrastructure tests come in two flavors:
-
Internal Penetration Tests
They focus on determining an internal attack surface – bypassing network access control, compromising internal servers and escalating privileges. An attacker can be either an anonymous person or an employee. -
External Penetration Tests
They focus on determining an external attack surface – public DNS configuration, all hosts exposed to the internet and services published on those servers. Here, an attacker comes from the outside.
Infrastructure security is just as important as web application security. Securing both of them gives us a sense of security
Infrastructure failure (outage) is mainly tested as a failover test. It is a technique that checks the system's ability to quickly move from one resource to another (e.g. virtual machine, database) and be fully ready to handle data without loss of data or availability.
In a typical case, an infrastructure security test is performed in the following steps:
- Acquiring resources that will be tested.
- Threat modeling – security analysis aimed at determining possible attack methods and most significant consequences.
- Establishing priorities, exclusions and dependencies.
- Performing tests. A client is informed on an ongoing basis about the identified key vulnerabilities.
- Reporting and analysis.
- Consultations on how to remove the vulnerabilities.
- Verification of the correct removal of vulnerabilities.
3. Create backup copies in accordance with good practices and check their integrity on a regular basis
The 3-2-1 backup strategy simply states that you should have 3 copies of your data (your production data and 2 backup copies) on two different media (disk and tape) with one copy off-site for disaster recovery.
5 best practices for cloud-based backup:
- Understand recovery objectives. Without recovery objectives, it's difficult to create an effective cloud backup strategy.
- Redundancy redundancy. It's never too much.
- Consider both data loss and downtime. Recovery Point Objective (RPO) and Recovery Time Objective (RTO) are two of the most important parameters of a disaster recovery or data protection plan.
- Think about systems and data categories.
- Consider using a recovery cloud if using on-premise solutions.
To sum up, to maintain the highest security and data availability of the most important elements of your infrastructure, you must meet a number of requirements. You can introduce some of them yourself right away. Another option to ensure the highest security and availability is entrusting the implementation of all the above mentioned measures to certified Cloud specialists.












