Machine Learning Basics for Developers

Imagine you're part of a development team that receives an ML model from a client. The model needs to be deployed as a live endpoint, accessible via HTTP for immediate data inferencing. In this critical scenario, understanding the key components of machine learning models it's not just beneficial – it's essential.
This guide aims to be your comprehensive companion in demystifying this complex landscape. We'll delve into aspects like data preprocessing and model selection, offer valuable insights into hardware optimization for model deployment, and explore the crucial yet often overlooked realm of model monitoring.
By the end of this machine learning basics guide, you'll have a holistic understanding of the machine learning pipeline, complete with actionable advice that can assist in decision-making and implementation.
Understanding machine learning basics
Machine Learning (ML) is a revolutionary approach to solving complex problems through computer algorithms. It is a subset of Artificial Intelligence (AI) and focuses on equipping computers with the ability to learn from data. The goal is to train a model – essentially a set of algorithms – to make predictions or provide answers based on that data.
For many, machine learning models might seem like a "black box," an entity with inputs and outputs but a mysterious internal mechanism. In reality, the model consists of several integral components:
- Architecture File: This is akin to the blueprint of your model, outlining the layers and how they connect. It's not just a description; it's the actual code that structures your model.
- Weights File: Developed during the training process, this file represents the state of the model. It includes information about which neural connections in the architecture are most or least valuable for making predictions.
- Metadata File: While you may not interact with this directly, it can contain valuable information like library versions and other technical specifics.
It's crucial to note the importance of machine learning metrics. These metrics help demystify the ‘black box,’ providing valuable insights into how well the model is performing. Common metrics include accuracy, precision, recall, and F1-score for classification problems, while metrics like Mean Squared Error (MSE), Root Mean Squared Error (RMSE), and Mean Absolute Error (MAE) are used for regression tasks. These metrics help machine learning engineers understand how well the model is performing on its intended task, providing both quantitative and qualitative insights.
Understanding model formats in machine learning
The machine learning landscape can be perplexing when it comes to model formats and their supporting libraries (you may think of them as runners). Each model format may have its own specialized library, which makes information gathering and practical application a daunting task. The situation becomes even murkier when you realize that some libraries can support multiple model formats, adding another layer to an already complex situation.
Model formats
- HDF5, legacy
- Keras
- TF (TensorFlow) SavedModel format, self-contained. Includes architecture, weights, and metadata, legacy
- PyTorch pth
- ONNX
- Core ML
- Python's Pickle
- More
ONNX (Open Neural Network Exchange) presents a promising solution to this chaos. Originating as a collaborative initiative but notably backed by Microsoft, ONNX aims to unify this fragmented ecosystem. With its converters, ONNX provides the capability to translate your existing models into a more universally accepted format, acting as a form of lingua franca in the complex world of model formats.
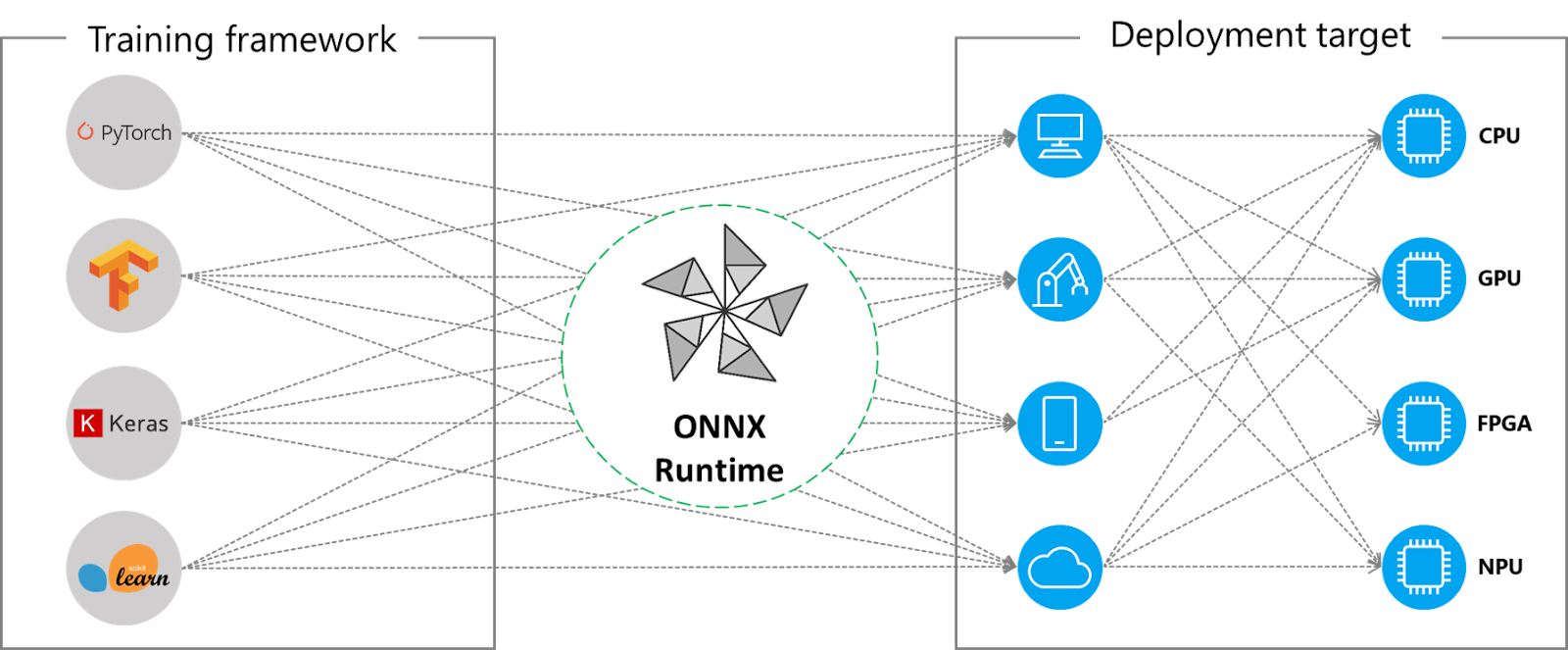
Source: https://onnxruntime.ai/
Understanding model signature in machine learning
Model signature refers to the specific inputs and outputs a machine learning model requires and produces. Similar to a function signature in programming, the model signature defines what data the model expects to receive and what kind of results it will deliver. Knowing this is crucial for anyone who interacts with the model, whether for training, fine-tuning, or making predictions.
While this information is typically available in documentation or from the person who trained the model, there are also tools to dissect a model's signature when this data isn't readily accessible. However, obtaining this information directly is generally the more straightforward route.
The model signature varies depending on the task the model is designed for. For instance, a large language model might work with strings for both inputs and outputs, requiring some pre-processing. In contrast, an image classification model wouldn't directly accept images but would instead require them to be transformed into vectors or other compatible formats.
Therefore, understanding the model signature is not just about knowing what data goes in and comes out, but also about comprehending how to properly format that data for interaction with the model.
Data preprocessing: What you need to know
Before you can feed data into a machine learning model, it often needs to be preprocessed. While your application's endpoint may accept data in common formats like JSON or images, the model might have different expectations. This discrepancy calls for effective preprocessing of the data to bridge the gap between the endpoint and the model.
Example of how uploaded image is preprocessed using transformers library
Preprocessing method signature presenting possible image transformations
To get the dataset into the shape that your model can understand, consult any available documentation or example notebooks. If possible, gaining access to the model's training pipeline can offer the most reliable insights into how to prepare your data for processing. This is particularly relevant for custom models developed within your organization.
Also, don't overlook off-the-shelf solutions. Companies like Hugging Face and NVIDIA provide well-documented models in their respective model libraries, commonly known as model hub. These can often save you the hassle of figuring out data preprocessing, as the necessary steps are typically well documented.
Navigating model deployment: Your options
Once you have a trained machine learning model, the next step is to deploy it for online inferencing. This can be done through various methods, depending on your project's needs and the level of automation. For instance, a one-time delivery of a model via email or a ticket might be simple, but it likely won't accommodate future retraining.
You could pull the model from a storage service like BLOB, especially if the client owns it and provides access. Alternatively, the model can be delivered as an artifact from a CI (Continuous Integration) pipeline, which aligns well with DevOps practices and MLOps practices. Another option is pulling the model from an internal model store—a specialized library containing multiple models trained within your organization. This store may offer additional information about the model's lineage, including how it was trained and the data used.
Whichever method you choose, it's important to consider whether the model will be updated or retrained in the future. In such cases, be vigilant about potential changes to the model's inputs and outputs, and consider implementing safeguards against invalid inputs. While third-party model hubs like Hugging Face offer well-documented, ready-to-use models, be aware that even these might undergo changes that could affect your application.

Machine learning deployment considerations
Hardware choices for model deployment: CPU vs GPU
When deploying a machine learning model, the choice of hardware can significantly impact performance. For compute-intensive tasks, particularly those involving multi-layered deep learning models, GPUs are often the more performant option. These specialized hardware components can process multiple operations in parallel, making them ideal for handling complex machine learning algorithms and large datasets.
However, CPUs may be more cost-effective for simpler models or applications where the computational demands are lower. While GPUs excel in speed, they also come with a higher cost, both in terms of initial investment and operational expenses.
To make an informed hardware choice, it's advisable to consult with a machine learning engineer who can assess the specific requirements of your model. This step is crucial before making any recommendations to stakeholders.
The importance of monitoring in model deployment
Monitoring deployed machine learning models goes beyond the conventional application metrics like CPU usage, memory, and response times. With machine learning models, monitoring takes on an additional layer of complexity as you'll need to keep track of both the inputs fed into the model and the outputs it generates. This is crucial because shifts or drifts in data can significantly impact a model's performance, sometimes leading to inaccurate or unreliable predictions.
To effectively monitor a machine learning model, you'll want to capture and analyze several types of data. First, consider application-level metrics like resource utilization and latency. These offer a general overview of system health. Second, focus on model-specific metrics, which may include the quality and type of input data as well as the outputs. For instance, if you're dealing with image recognition models, you might need storage solutions like blob storage to keep a record of the images being processed.
Options for implementing robust monitoring solutions vary. Cloud services like Azure or Google Cloud offer out-of-the-box monitoring capabilities that can be both comprehensive and convenient. However, these services usually come at a premium cost. If your model has simple inputs and outputs—like text-based large language models—you might find it cost-effective to build your own monitoring solution.
Access goodie bag: A repository of practical examples
Imagine diving into a "goodie bag" full of code examples specifically designed for implementing machine learning models. This repository serves as a practical guide for those who wish to delve deeper into the complexities of deploying machine learning models. It features two primary examples to help you get started.
Fast API inference example
The first example is a Fast API endpoint designed for model inference. Dockerized for hassle-free deployment, this code snippet leverages the Transformers library from Hugging Face, enabling a straightforward model-loading process. This example demonstrates how to read an image, preprocess the data, and feed it into the model for predictions. However, be cautious when pulling data from the internet. In the demonstration, this approach led to timeouts, underlining the importance of optimizing the model-loading process, especially in a production environment.
Azure online endpoint
The second example is tailored for those interested in Azure-based deployments. Using Azure AI libraries, this example guides you through the process of specifying critical model details, including the path, type of deployment, and machine size requirements. It's worth noting that your ability to execute this example may be constrained by your Azure subscription tier. In the demonstration, limitations existed due to an inability to spin up sufficiently large machines. Additionally, be prepared to work with data in JSON format, as this Azure example has specific requirements for data preprocessing.
GitHub practical resources
These examples are not just theoretical constructs; they are available for download from GitHub, allowing you to run them locally or even deploy them on Azure. These practical resources not only facilitate learning but also act as a stepping stone for your own deployments. When exploring these examples, keep in mind the requirements, whether it's data sources, data formats, or deployment platforms like Azure, which offer robust yet potentially expensive solutions.
Feel free to explore this repository and put these examples to the test. Whether you're running them locally or considering Azure deployment, this "goodie bag" serves as a treasure trove of insights for anyone interested in the practical aspects of machine learning deployment.
Final thoughts
In summary, implementing a machine learning model involves a complex yet rewarding process that goes beyond traditional programming. It draws from various fields of computer science to recognize patterns in historical data for tasks like natural language processing, speech recognition, and computer vision.
Understanding the basics of machine learning is useful—right from model training and selection to ongoing monitoring and evaluation. As we move further into a data-driven era, mastering these key aspects empowers development teams to build, deploy, and manage more intelligent systems.
Key takeaways
- Know Your Model Inside and Out: Thoroughly read all documentation and consult with the model's creators if possible.
- MLOps Is Your Best Friend: Use MLOps frameworks and principles to ensure smooth collaboration between teams and to streamline the machine learning pipeline from development to production.
- Resource Allocation Matters: CPUs and GPUs have their own sets of advantages and disadvantages. Your choice between the two should be based on the model's computational needs, latency requirements, and your budget.
- Monitoring is More Complex Than You Think: Unlike basic web applications, machine learning models require a unique set of monitoring tools and techniques. This may involve monitoring the actual inputs and outputs of the model and setting up alerts for anomalies.
- Practical Experience is Invaluable: Before deploying a model in production, run through some real-world examples. These can highlight unforeseen issues and give you a clearer understanding of the entire system.










